Befüllen und Abfragen einer Entscheidungstabelle mit Defaultwerten und Ausnahmen. Dieser Artikel basiert auf einem OTN-Post:
Warum
Im Laufe der Zeit entwickelte sich Code, der für Entscheidungen im Programm zuständig ist, zu einem Wust aus mehrfach geschachtelten IF Anweisungen. Wir entschieden uns dazu es als Entscheidungstabelle zu implementieren.
Wie
Weil es mehr als 20.000 mögliche Kombinationen an Attributen gibt, wäre eine Tabelle, die alle Ausprägungen enthält nicht wartbar.
Hier ein vereinfachtes Beispiel mit Kunden, die in verschiedenen Regionen sind, ein Attrinut kann Y oder N sein und ein Attribut ist von anderen Eigenschaften abgeleitet und es gibt keine Tabelle, die alle möglichen Werte enthält; natürlich sollte es dafür eine Tabelle geben, aber das ist eine andere Geschichte.
Die Tabelle ist hierarchisch aufgebaut, d.h. dass jede Spalte mehr Gewicht hat als die rechts davon liegenden.
Das Ergebnis ist entweder Y (YES) oder N (NO)
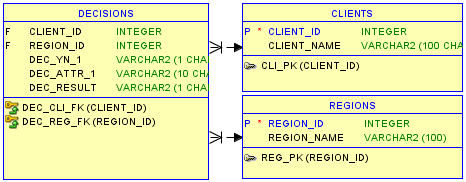
Skript und Daten
DROP VIEW ranked_decisions;
DROP TABLE decisions;
DROP TABLE clients;
DROP TABLE regions;
CREATE TABLE clients
(
client_id INTEGER NOT NULL
,client_name VARCHAR2 (100)
) ;
ALTER TABLE clients ADD CONSTRAINT cli_pk PRIMARY KEY ( client_id ) ;
CREATE TABLE regions
(
region_id INTEGER NOT NULL
,region_name VARCHAR2 (100)
) ;
ALTER TABLE regions ADD CONSTRAINT reg_pk PRIMARY KEY ( region_id ) ;
CREATE TABLE decisions
(
client_id INTEGER NOT NULL
,region_id INTEGER
,dec_yn_1 VARCHAR2 (1 CHAR)
,dec_attr_1 VARCHAR2 (10 CHAR)
,dec_result VARCHAR2 (1 CHAR)
) ;
ALTER TABLE decisions ADD CONSTRAINT dec_cli_fk FOREIGN KEY ( client_id ) REFERENCES clients ( client_id ) ;
ALTER TABLE decisions ADD CONSTRAINT dec_reg_fk FOREIGN KEY ( region_id ) REFERENCES regions ( region_id ) ;
INSERT INTO clients (client_id,client_name) VALUES (1,'A');
INSERT INTO clients (client_id,client_name) VALUES (2,'B');
INSERT INTO clients (client_id,client_name) VALUES (3,'C');
INSERT INTO clients (client_id,client_name) VALUES (4,'D');
INSERT INTO clients (client_id,client_name) VALUES (5,'E');
INSERT INTO regions (region_id,region_name) VALUES (10,'BY');
INSERT INTO regions (region_id,region_name) VALUES (11,'BW');
INSERT INTO regions (region_id,region_name) VALUES (12,'HE');
INSERT INTO regions (region_id,region_name) VALUES (13,'TH');
INSERT INTO regions (region_id,region_name) VALUES (14,'HH');
--Default for each client
INSERT INTO decisions (client_id,region_id,dec_yn_1,dec_attr_1,dec_result)
VALUES ( 1, NULL, NULL, NULL, 'N');
INSERT INTO decisions (client_id,region_id,dec_yn_1,dec_attr_1,dec_result)
VALUES ( 2, NULL, NULL, NULL, 'N');
INSERT INTO decisions (client_id,region_id,dec_yn_1,dec_attr_1,dec_result)
VALUES ( 3, NULL, NULL, NULL, 'Y');
INSERT INTO decisions (client_id,region_id,dec_yn_1,dec_attr_1,dec_result)
VALUES ( 4, NULL, NULL, NULL, 'N');
INSERT INTO decisions (client_id,region_id,dec_yn_1,dec_attr_1,dec_result)
VALUES ( 5, NULL, NULL, NULL, 'Y');
Die Abfrage
CREATE OR REPLACE VIEW ranked_decisions AS
WITH all_combinations AS (
--Generiere alle möglichen Kombinationen der Attribute
SELECT cli.client_id
,reg.region_id
,yn.yn_1
,attr.attr_1
,dc.dec_result
-- Wertung der Ergebnisse
-- Gibt es ein Ergebnis mit dc.client_id <> NULL, wird ein Wert von 8 genommen
-- Entsprechend für dc.region_id 4, dc.dec_yn_1 2 und für dc.dec_attr_1 1
-- Dadurch kann man sicherstellen, dass Kombinationen, die einen Treffer in der Tabelle haben,
-- höher gewertet werden, als generierte Kombinationen
,ROW_NUMBER () OVER (
PARTITION BY cli.client_id,reg.region_id,yn.yn_1,attr.attr_1
ORDER BY CASE WHEN dc.client_id IS NULL THEN 0 ELSE 8 END
+ CASE WHEN dc.region_id IS NULL THEN 0 ELSE 4 END
+ CASE WHEN dc.dec_yn_1 IS NULL THEN 0 ELSE 2 END
+ CASE WHEN dc.dec_attr_1 IS NULL THEN 0 ELSE 1 END
DESC
) r
FROM clients cli
CROSS JOIN regions reg
CROSS JOIN (
SELECT 'Y' yn_1 FROM dual UNION ALL
SELECT 'N' yn_1 FROM dual
) yn
CROSS JOIN (
SELECT 'LA' attr_1 FROM dual UNION ALL
SELECT 'M' attr_1 FROM dual UNION ALL
SELECT 'SR' attr_1 FROM dual UNION ALL
SELECT 'N' attr_1 FROM dual
) attr
JOIN decisions dc
ON ( (cli.client_id = dc.client_id OR dc.client_id IS NULL)
AND (reg.region_id = dc.region_id OR dc.region_id IS NULL)
AND (yn.yn_1 = dc.dec_yn_1 OR dc.dec_yn_1 IS NULL)
AND (attr.attr_1 = dc.dec_attr_1 OR dc.dec_attr_1 IS NULL)
)
)
SELECT ac.client_id
,ac.region_id
,ac.yn_1
,ac.attr_1
,ac.dec_result
FROM all_combinations ac
WHERE r = 1;
SELECT dec_result
FROM ranked_decisions
WHERE client_id = 4
AND region_id = 14
AND yn_1 = 'N'
AND attr_1 = 'LA';
Natürlich bekommen wir ein 'N'.
Die Ausnahmen
Fügen wir ein paar Ausnahmen hinzu
--Default für die Region HH ist Y für die Kunden A und D
INSERT INTO decisions (client_id,region_id,dec_yn_1,dec_attr_1,dec_result)
VALUES ( 1, 14, NULL, NULL, 'Y');
INSERT INTO decisions (client_id,region_id,dec_yn_1,dec_attr_1,dec_result)
VALUES ( 4, 14, NULL, NULL, 'Y');
Jetzt bekommen wir für dieselbe Abfrage ein 'Y'
Weitere Ausnahmen könnten sein
-- Kunde A ist Y wenn die Region BY ist
INSERT INTO decisions (client_id,region_id,dec_yn_1,dec_attr_1,dec_result)
VALUES ( 1, 10, NULL, NULL, 'Y');
--außer wenn Attribut 1 = LA
INSERT INTO decisions (client_id,region_id,dec_yn_1,dec_attr_1,dec_result)
VALUES ( 1, 10, NULL, 'LA', 'N');
-- Kunde D ist Y wenn das YN-attribute Y ist
INSERT INTO decisions (client_id,region_id,dec_yn_1,dec_attr_1,dec_result)
VALUES ( 4, NULL, 'Y', NULL, 'Y');
Unsere Entscheidungstabelle hat nun folgende Daten
CLIENT_ID REGION_ID D DEC_ATTR_1 D
----------- ----------- - ---------- -
1 N
2 N
3 Y
4 N
5 Y
1 14 Y
4 14 Y
1 10 Y
1 10 LA N
4 Y Y